thesisProject
Main menu:
Inferring Social Relationships from Mobility Patterns of Location Based Online Social Networks Users
Vahan Babushkin
It is commonly accepted, that we tend to make social ties with people who live near us. However, it is not the case for online social networks’ users, whose friends can be living thousands kilometers away. Apart of making friends, location-based social networks (LBSN) allow their users to check-in in different locations. Those check-ins can be deployed to extract user’s mobility patterns, that can help us to study the regularity of users' movements and to discover friendship ties among them. We propose a method for predicting social relationships between members of LBSN using their mobility data. The potential application of this model can be found in friend recommendation systems.
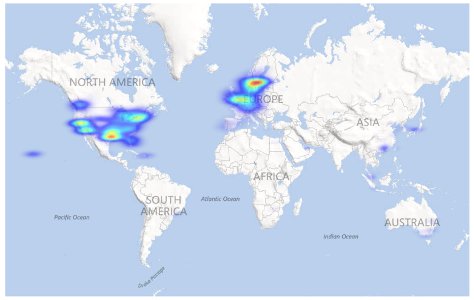
All Gowalla location based online social network users’ check-ins distribution around the world.
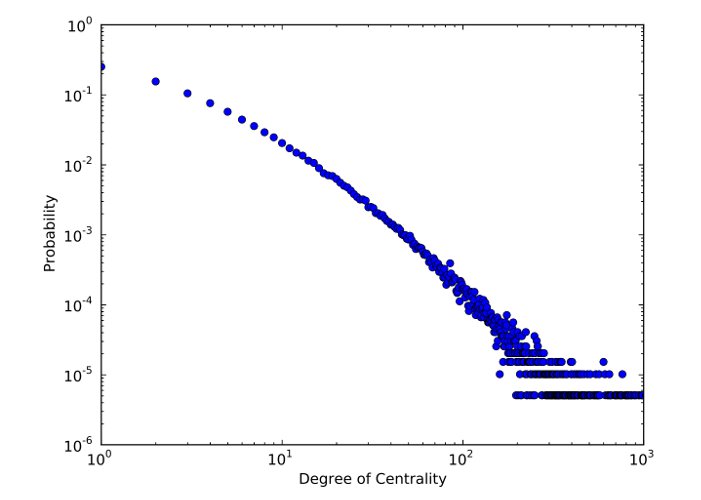
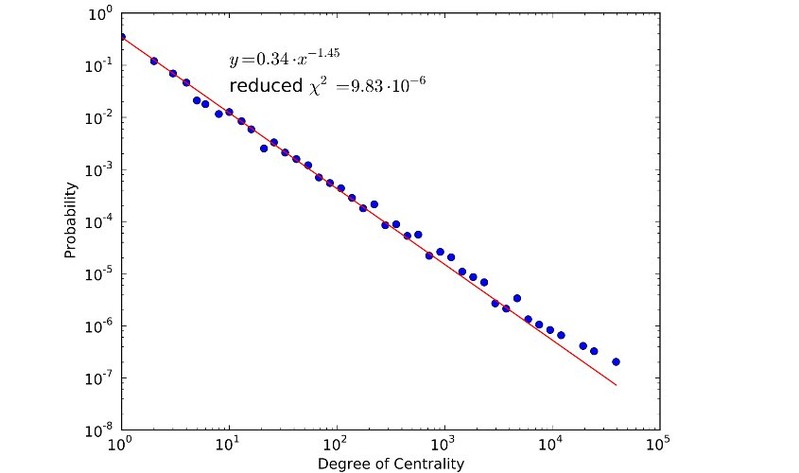
We adopted the data from Gowalla LBSN, publicly available on the Stanford Large Network Dataset Collection (SNAP). It contains users’ check-ins, along with date and time, location coordiantes and location ID. The users’ relationships dataset is collected by using public API, in form of undirected graph, where users are represented as nodes and relationships between them as edges, in overall, totalling to 950,327 edges and 196,591 nodes. In total, there are 6,442,890 check-ins records of 196,591 users collected over the period of February 2009 to October 2010.
The brief analysis of Gowalla network demonstrated its’ heavy-tailed behavior, reflecting the fact, that the majority of users prefers to create a few friendship ties in contrast with the minority of most influential nodes, who can have tens or even hundreds of thousands friends. A simple statistics clearly demonstrates this tendency. The diameter of Gowalla LBSN network (12) as well as high values of clustering coefficient (0.316) point out on its’ small-world properties. The whole Gowalla social network appears as a whole connected component, i.e. any vertex is reachable from another one, chosen randomly. The low values of average shortest path length (4.627) again witness about the small-world network features.
We preprocess the data to extract different mobility features which, to some extent, can indicate relationship between users. For example, the location entropy reflects the number of unique individuals visited the place as well as a proportion of their appearance in a given location, giving an idea about location diversity. The higher the location entropy, the more popular the current location among visitors, therefore, the lower its privacy. For example, users’ homes or individual apartments are expected to have low entropy, while the location entropy of public places like cafes or restaurants is relatively high. And, therefore, if both users visit the same place with low location entropy, the probability that they are friends is higher, than in the case of place with high location entropy. Other features include users co-locations, frequency of visits, user count for given location, distance between their homes, number of mutual neighbours, etc. totaling to 49 features.
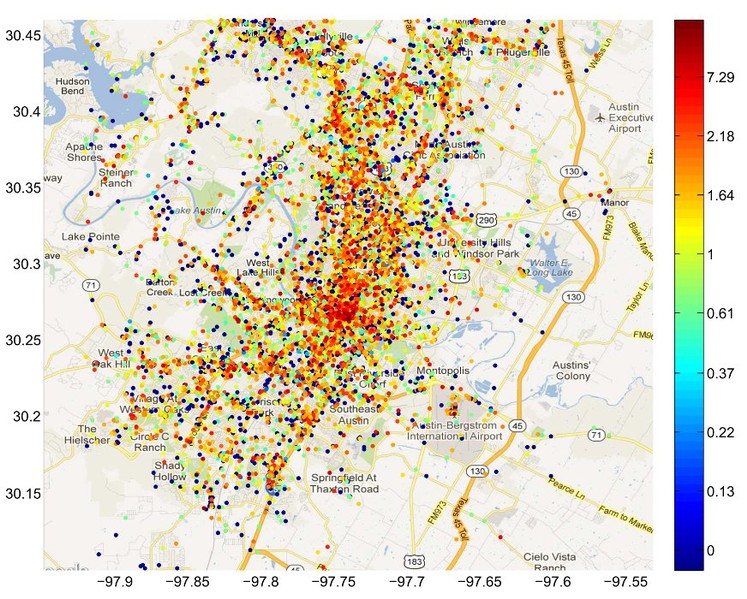
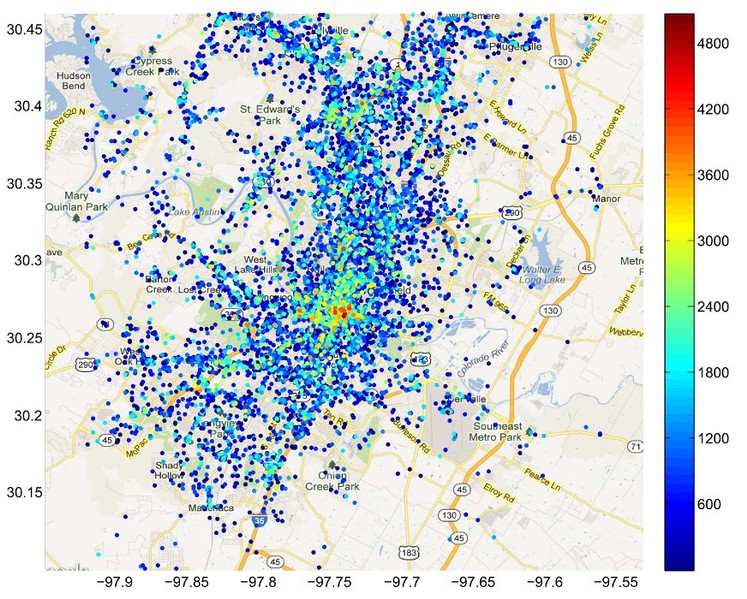
Location entropy values for Austin, TX.
Location frequency values for Austin, TX.
In order to reduce the dimensionality of feature space we tried different feature selection methods, like Fisher's discriminant ratio, Student's t-test and several others. It helped us to come up with the reduced set of 10 most significant features. Interestingly, the most significant are found to be those, related to the number of mutual neighbors for given pair of users and their neighborhood overlap. It reflects the notion that people more likely to make friendship ties with friends of their friends. Significance of neighborhood overlap group of features points out that the people, visiting similar places may have similar interests, and, most probably, be friends. The high significance level of co-location features is due to the increase in probability of social ties with the number of co-locations within some temporal interval. The diversity of unique individuals, in places, visited by given pair of users is also significant. It means, that the more places, visited by high number of unique individuals two given users attend together, the higher probability of friendship tie between them.
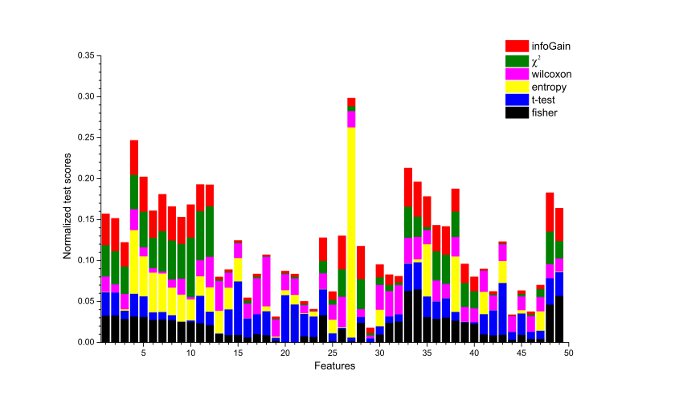
Comparing different feature selection methods.
Online Location Based Social Networks usually exhibit a severe imbalanced distribution of friends/non-friends instances (about 1:800) that also reflects a real situation, when the number of friends in big communities is relatively small in comparison with the number of non-friends. Since the performance of the classifier is trained on undersampled dataset is higher than trained on oversampled one, we deploy the undersampling technique to deal with the underrepresented friendship instances. Coupled with Random Forests model, it allows to recover around 75% of actual friendships based on the users’ mobility features, taking into account even the first-time users (with one check-in record). Further, this approach can be deployed in friendship recommendation systems, in security domain as well as for promotion of sustainable behavior among LBSN users.