twitterGlobalHappinessProject
Main menu:
Sensing Global Happiness, Diurnal Rhythms and Topics Through Social Media (Twitter)
Aamena Ali Al Shamsi, Vahan Babushkin, Vimitha Manohar
Social Media is a set of interactive applications and platforms for generating, sharing and exchanging information. It constantly becomes ubiquitous nowadays with emerging popular sites like Facebook and Twitter. Due to its popularity, Social Media can serve as an indicator of some human activities, emotions and interests that can reveal homophily patterns between areas, having some other parameters, totally irrelevant to Social Media, in common. In this project we analyze tweets from countries with a similar Human Development Index (HDI) to reveal how far this similarity affects user - generated content. Correlation between parameters inferred from Tweets and HDI can be used as a less expensive approach for obtaining different socioeconomic indices.
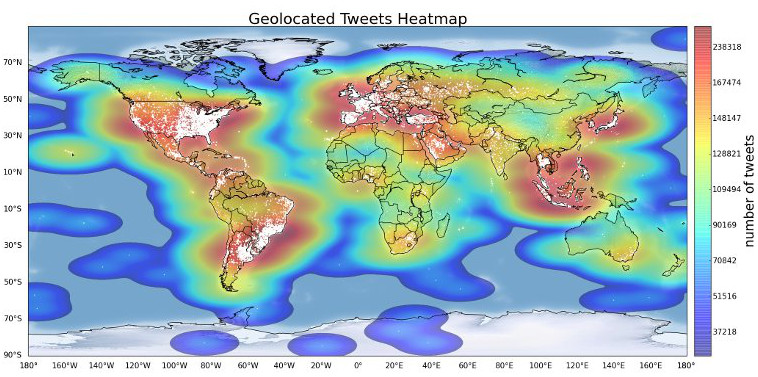
Distribution of all geolocated tweets collected within one month.
Human development index (HDI) is a summary measure of average achievement in key dimensions of human development: health, education and income. The HDI is the geometric mean of normalized indices for each of the three dimensions. Our hypothesis is that countries that are similar according to (HDI) share common patterns measured through social media (tweets) given the heterogeneity between countries in terms of the studied variables.
To prove or reject our hypothesis, we divided the countries with sufficient numbers of geolocated Tweets collected within a month into 4 strata according to their HDI values. To ensure homogeneity within a stratum and heterogeneity between strata we used k-means clustering. The following clusters were obtained:
| Cluster | Number of Countries | HDI range |
| 1 | 33 | 0.83- 0.944 |
| 2 | 38 | 0.731-0.827 |
| 3 | 25 | 0.614-0.722 |
| 4 | 18 | 0.393-0.586 |
We collected about 50,000 geolocated tweets, which constituted less than 10% of total number of tweets, and then assigned each of them to the corresponding stratum. A stratified sampling techniqie was adopted to generate a representative subset for each stratum. After sampling, we applied a hedonometer approach to each representative set and calculated the aggregate happiness of each stratum. In other words, we considered average happiness per country and then aggregate all values, obtained per stratum.


The top 150 hashtags for UAE.
The top 150 hashtags for Russia.
We also tried to find out the difference between topics people from each stratum are interested in. For this purpose, we applied the Latent Dirichlet Allocation (LDA) approach to extract topics from collected Tweets both on the country level and on the stratum level. All non-English tweets were translated using Google Translator (Goslate) API. Then, tweets were aggregated into bag-of-words for each country and stratum. These bags-of-words were fed into the LDA model. A slight difference in topics of interest was detected within different countries. However, this evidence was too weak to support our hypothesis. Regarding the topics within strata, there was no statistically significant heterogeneity detected either.
In all cases the ANOVA test proved insufficient evidence of heterogeneity between strata. It means that Human Development Index cannot be considered as a suitable indicator for global patterns.
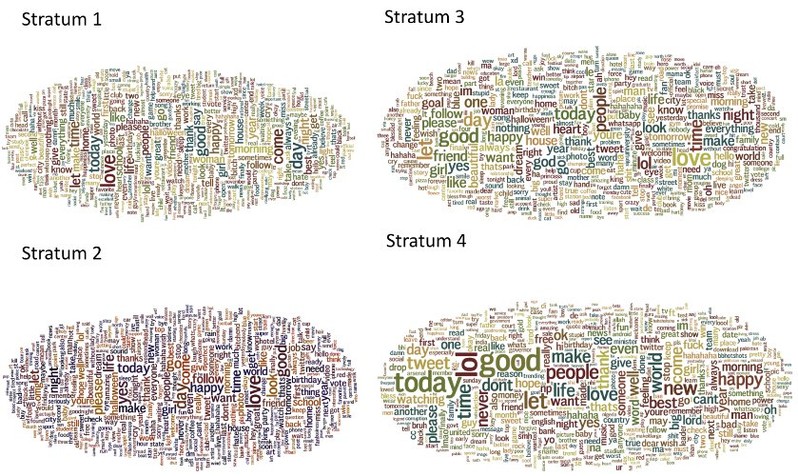
The top topics of interest for each stratum.